在多年来构建、发展稀土单质和Sm-Co基合金体系数据库的基础上,近日,北京工业大学宋晓艳教授团队在数据驱动新材料设计方面取得了新的突破,研究工作以“Selecting Doping Elements by Data Mining for Advanced Magnets”为题发表于Chemistry of Materials上。该工作基于构建的Sm-Co基多元合金数据库及饱和磁化强度数据集,结合数据挖掘与机器学习,筛选饱和磁化强度友好型掺杂元素,显著促进了高性能新材料的研发进程。这种在大范围内快速、准确地筛选添加元素的方式,可推广应用到多种可调制性能的多元材料的成分设计中。
(论文图片摘要)
论文链接:
https://pubs.acs.org/doi/10.1021/acs.chemmater.9b03379
该论文博士生刘东为第一作者,宋晓艳教授为通讯作者。
数据库建设背景
该研究团队在2006-2013年期间构建了稀土单质与Sm-Co化合物数据库,发展成为我国材料科学数据共享网中的稀土基础数据资源节点。以此为研究背景,近年来团队以高温永磁合金代表体系Sm-Co基多元合金为例,建成了面向数据驱动材料设计的专用数据库,数据实现了高度结构化,可满足基于深层次信息的数据检索、数据结构转换、材料设计专用数据集抽取等需求。本论文所报道的研究即是基于该专用数据库开展的材料设计目标之一。
数据驱动材料设计
本文添加元素筛选的方法是在对数据库中饱和磁化强度相关数据进行挖掘时提出的。在开发磁性材料时,以往常凭经验避开那些对饱和磁化强度不利的元素。在这项工作中,从构建的专用数据库中抽取产生Sm-Co基合金饱和磁化强度数据集,以此开展数据驱动的材料设计开发。
通过成组数据识别,发现了分组线性回归参数是用于分析饱和磁化强度多种影响因素的重要特征,进而提出了评价掺杂元素对合金饱和磁化强度影响的指标(文中记为SR),将研究目标从对饱和磁化强度的预测聚焦到对掺杂元素的筛选上。通过机器学习在已知掺杂元素的SR与掺杂元素典型特征之间建立了关联,实现了在元素周期表大范围内评估掺杂元素对Sm-Co基合金饱和磁化强度的影响。
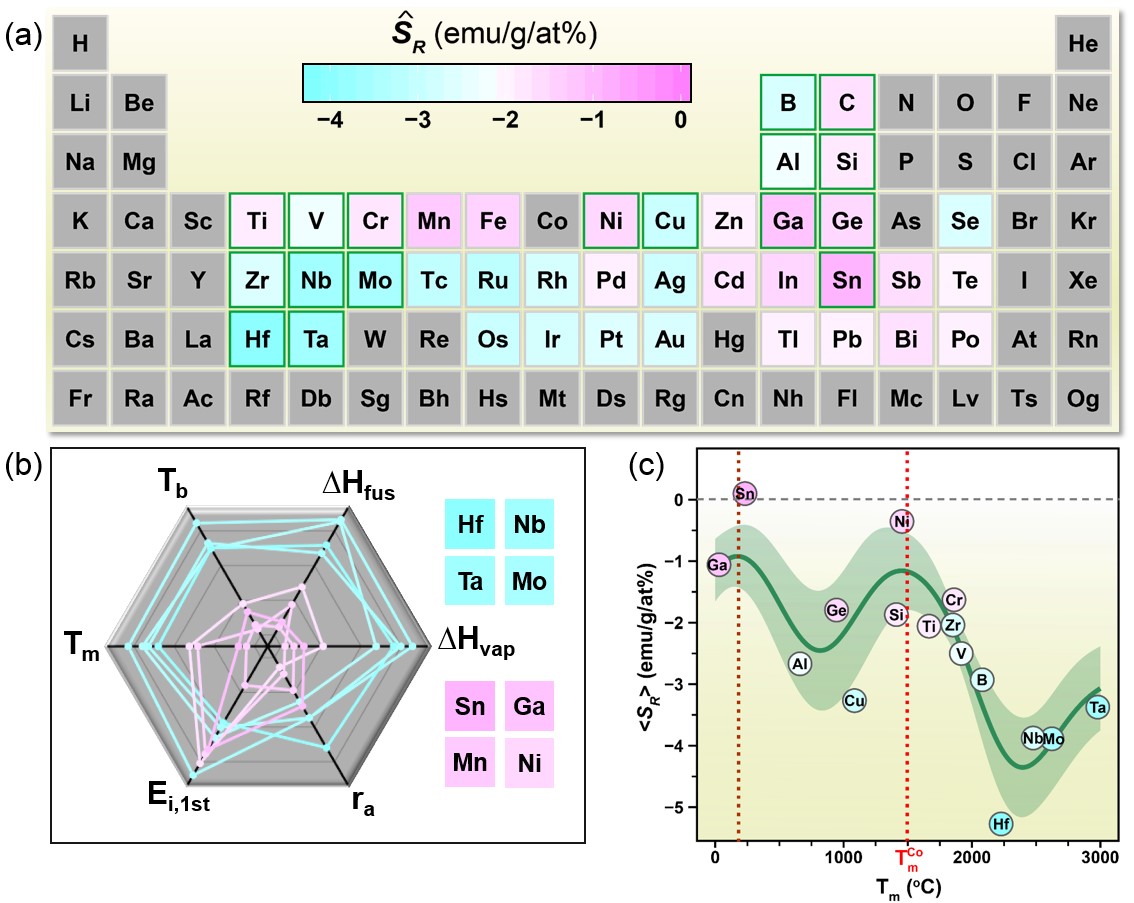
(图1. 预测的各掺杂元素对Sm-Co基合金饱和磁化强度的影响,及其与元素已知特征的关系)
根据上述发现的规律可全面、准确地筛选掺杂元素,进而高效指导成分设计和实验制备。利用优选的元素开展实验,对Sm-Co基合金进行掺杂,实际结果表明优选的元素均能保持与对应的Sm-Co二元合金同等的高饱和磁化强度,且与预测结果符合很好,表明这些掺杂元素具有非常重要的利用价值和开发潜力。进而,结合工艺设计和微观组织优化,开发获得了一批具有优越综合磁性能的新型Sm-Co基永磁合金。
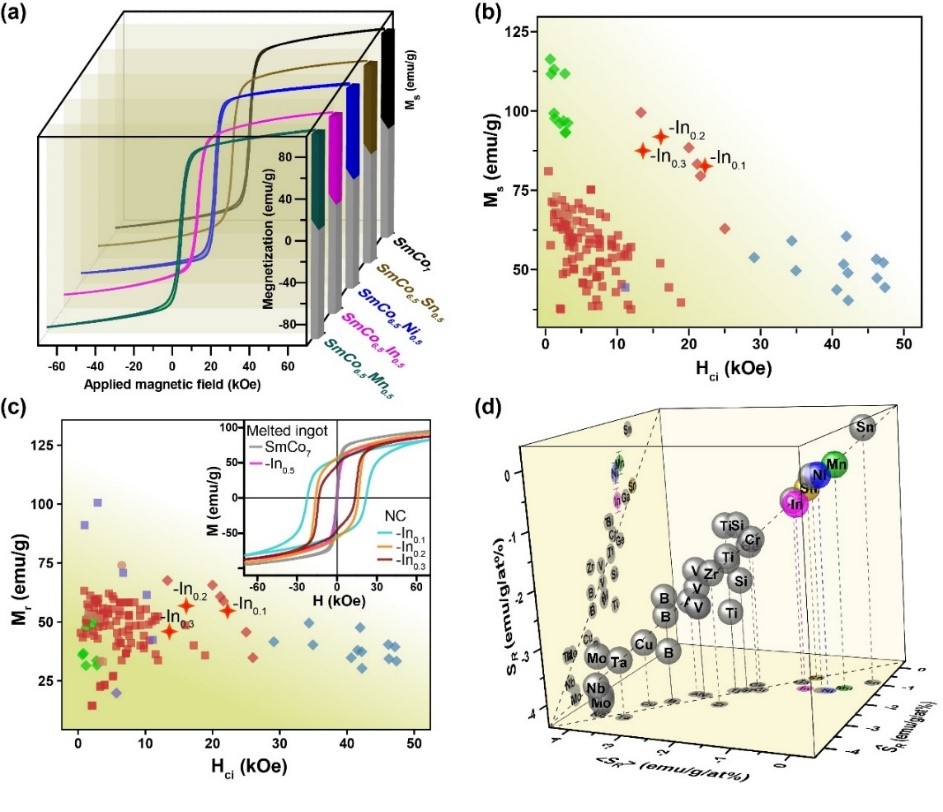
(图2. 以优选的掺杂元素进行成分设计和实验制备,验证了预测结果,并将综合磁性能提高至先进水平)
方法适用性
添加元素的选择是材料成分设计过程中非常重要的环节。然而,被选元素的应用场景复杂多变,常常难以找到有效的理论进行指导。论文建立的这种方法可以推广到多种掺杂改性中的元素优选问题。在这些问题中,往往已报道的文献中有大量探索性的实验或理论计算数据,但受限于实验周期或实验条件,很难遍历所有元素。通过数据变换或可视化技术等对建立的数据集进行探索性分析,找到受元素种类主导的参量,以之作为定量(对应回归算法)或定性(对应分类算法)的判据对已有的数据进行评价。利用机器学习找到该参量和元素的已知属性之间的关系,可将该参量合理推广到所有可利用的元素上,从而达到从更大范围筛选元素的目标。进一步,利用特征筛选或变量重要性分析等对模型进行深入解读,可以获得具有解释性的知识或规律。
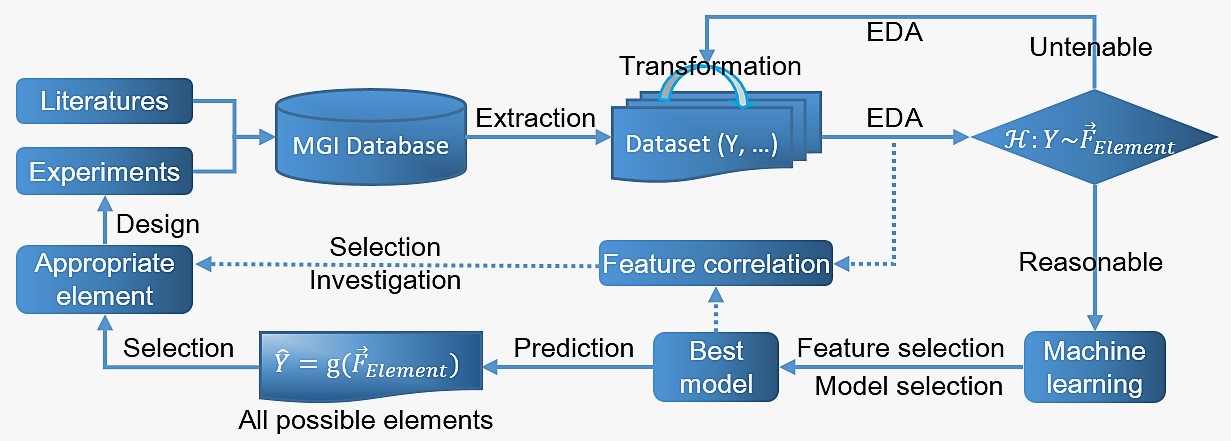
(图3. 针对掺杂改性的材料设计问题提出的数据驱动策略示意图)
专用数据库应用展望
该论文是从面向数据驱动材料设计的专用数据库出发,构建数据集、处理数据并结合机器学习等技术来加速材料设计的一个示例。随着数据数量增加和质量提升,专用数据库中可挖掘的研究主题会越来越多,面向更多主题的数据驱动高性能新材料的设计和开发会不断推进和扩展。
本研究方向得到了国家重点研发计划项目“材料基因工程专用数据库和材料大数据技术”和课题“多尺度高通量材料计算工具集成与统一接口开发”及国家杰出青年科学基金项目的资助。
详情点击查看全文:
https://pubs.acs.org/doi/10.1021/acs.chemmater.9b03379